Hey guys! Sorry for the delay in publishing this post, I wanted to spend some time on working on a project that I could discuss. This project has probably been one of my favorite ones so far due to its universal relatability. I chose to venture into the field of natural language processing, NLP, and utilize my knowledge from this amazing yet comprehensive topic to analyze and extract information from my Spotify playlists. I learned about a specific application of NLP called sentiment analysis and decided to determine the polarity of my playlists.
In this post, I will introduce natural language processing and sentiment analysis, delve into project implementation, discuss future work and conclude with a fun thought.
What is NLP, or Natural Language Processing?
It is a field of AI, Artificial Intelligence, whose primary purpose is to effectively train and teach machines the fundamentals of human language. It utilizes linguistic principles and machine learning methods to study language syntax, rules, and structure to create intelligent programs that can understand and extract meaning from texts and speech. One example of an NLP program are chatbots that answer any questions you have about a company’s products or services. They aim to reduce the need of employing representatives to personally address ordinary questions that can easily just be answered in a matter of seconds by analyzing the language of a customer’s inquiry and returning information from a database that most closely resembles the question’s context and answers the intent.
Sentiment Analysis
The main subtopic of NLP that I studied and used in this project is sentiment analysis, which is the process of classifying text as positive or negative. There are many machine learning algorithms that accomplish this, such as Naive Bayes, Support Vector Machines, k-Means Clustering, etc. These are divided into supervised and unsupervised methods, where the model either trains on data that already has or doesn’t have a label assigned to each data point. I decided to research and use a supervised algorithm, specifically Naive Bayes, since it is straightforward and concise to understand due to the data points having a “positive” or “negative” label associated with it.
Project Implementation
Technologies and Frameworks
I used the Python NLP library, nltk, to normalize my data and perform sentiment analysis, Spotify API for retrieving a playlist items, Genius API to retrieve song lyrics, and Flask for routing requests and server-side development.
Obtain Test Data
I retrieved the playlist id from the user by instantiating a Spotify client using a client token provided to me by the Spotify Developer Dashboard and invoking the playlist_items method using the id as a parameter to retrieve the songs. Then, by iterating through every song in the playlist, I performed a GET request to the Genius API to retrieve lyrics using the song name and artists as a search query.
Before sending in the lyrics to the model for classification, I had to learn some of the basics of tokenizing and normalizing data in sentiment analysis. Here’s a song lyric that I’ll be breaking down in the process:
“How you so cold, when the sun is so blinding?”
Tokenization
It would be easy to just simply pass in full length sentences to a model so it can decipher them by itself. However, this is definitely a naive approach as complex models rely on data that has been broken down to bits and pieces so that it’s easily digestible, in this case words and punctuation. This is where tokenization comes in, which breaks a string of words semantically into tokens. The process splits the sentence or phrase based on whitespace or punctuation, however you can decide the delimiter.
Lyric Output
“How you so cold, when the sun is so blinding?” => [“How” “you” “so” “cold” “,” “when” “the” “sun” “is” “so” “blinding “?“]
Lemmatization
Now that we have our sentence broken down to its fundamental components, where do we go from here? Well, we have to break these words down even further. We have to normalize them, since many of these words could be different forms of each other, whether it’s in the past, present, or future tense. Lemmatization is the process of analyzing the context and structure of a word before converting it to its normalized form. To do this, we use a Part of Speech tagging algorithm that determines the position of the word in the sentence. As a result, we receive information about the tags.
- NN: common, singular noun
- NNP: proper, singular noun
- VBN: past participle, verb
Using this information, we pass the token and its corresponding tag to the WordNetLemmatizer, a lemmatization function provided by the nltk library. Additionally, we also filter out any words that are a stop word, which are words that are insignificant to determining the semantics of a sentence. This is helpful in the sense that it reduces our training data size and allows the model to focus on important words.
Lyric Output
[“How” “you” “so” “cold” “,” “when” “the” “sun” “is” “so” “blinding “?“] => [“so” “cold” “sun” “so” “blind“]
Training and Testing
I applied this process to my training data that consists of the Twitter tweets, and passed it into the Naive Bayes classifier so it could train on it. The training functionality is abstracted from me since it just requires me to use the NaiveBayes class provided from the nltk library, however I will quickly explain how this works.
Naive Bayes is a classification system that utilizes Bayes Theorem, which determines the probability of a conditional event. For our purposes, the training basically iterates through all the words, determines the frequency of each word in all of the positive and negative tweets, and calculates the log likelihood of the word based on its probabilities of being positive or negative. Then, when the classifier tests itself on new lyrics, it will obtain the total likelihoods of all the unique words and if the result is greater than zero then it is positive, or negative if it’s less than zero.
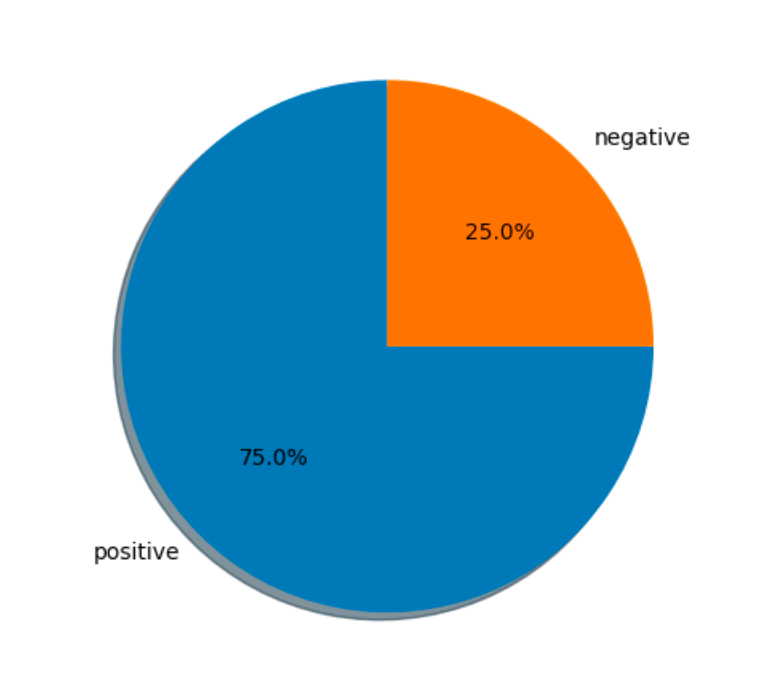
After training the model using this method, it tests itself on lyrics from songs in the playlist.
Future Work
I learned a great deal from this project as it incentivized and pushed me to reinforce my understanding of the principles of predictive modeling. Overall, what I’ve understood is that text classification is an unexplored and complicated task as it requires us to continuously study the depths of language structure and syntax.
One limitation that I see currently with my implementation is that the source of my training data is semantically different than my testing data. Firstly, I observed that tweets incorporate the use of emoticons and images to convey their message in addition to the text. However, song lyrics are solely based on text, so there are significantly less nuances that need to be accounted for during classification. Moving forward, I will definitely research datasets that are solely text based and closely resemble the semantics of lyrics as this will decrease the number of false positives and negatives.
Another limitation is utilizing supervised learning methods opposed to those of unsupervised learning. By training a model on predefined labels doesn’t fully allow developers or researchers to truly understand the linguistic derivations of words. They’re simply classifying new text based on rules that have already been laid out for identifying word polarity. Moving forward, I will definitely want to incorporate phonetics and morphology, in addition to syntax and semantics, into an unsupervised learning algorithm such as k-means clustering, which groups data solely on their values. This will allow me to fully delve into the basics of linguistics and integrate more properties to be studied and evaluated when grouping likewise words together and reaching a goal of effective text classification.
Fun
I recently just rewatched Arrival from Denis Villeneuve, which is a movie about a linguist that is tasked with understanding and deciphering the intent of extraterrestrials landing on Earth. The movie deals with the concept of the Sapir-Whorf hypothesis, which is a claim that the semantic structure of a language can influence the way a speaker forms their perceptions of the world. For example, one of the Nordic languages has different words for water, such as using water for bathing versus drinking. As the linguist tries to assimilate the alien language, she begins to understand that their perception of the flow of time is nonlinear and, for obvious reasons, clashes with her perception of her life. If I think about how this could impact the field of natural language processing, there are numerous implications that can be derived from this. Simply categorizing words as positive or negative is one small feat that has been accomplished as there are an extensive number of parameters to account for. Models have to be able to train on languages that each convey a distinctive understanding of fundamental workings of the world, whether it’s the flow of time or the intensity of events. They will have to make sure to obtain the means of compartmentalizing and housing all of this data so it doesn’t overflow or crash.
Thank you for taking the time to read this blog and I hope you enjoyed it!

Leave a comment